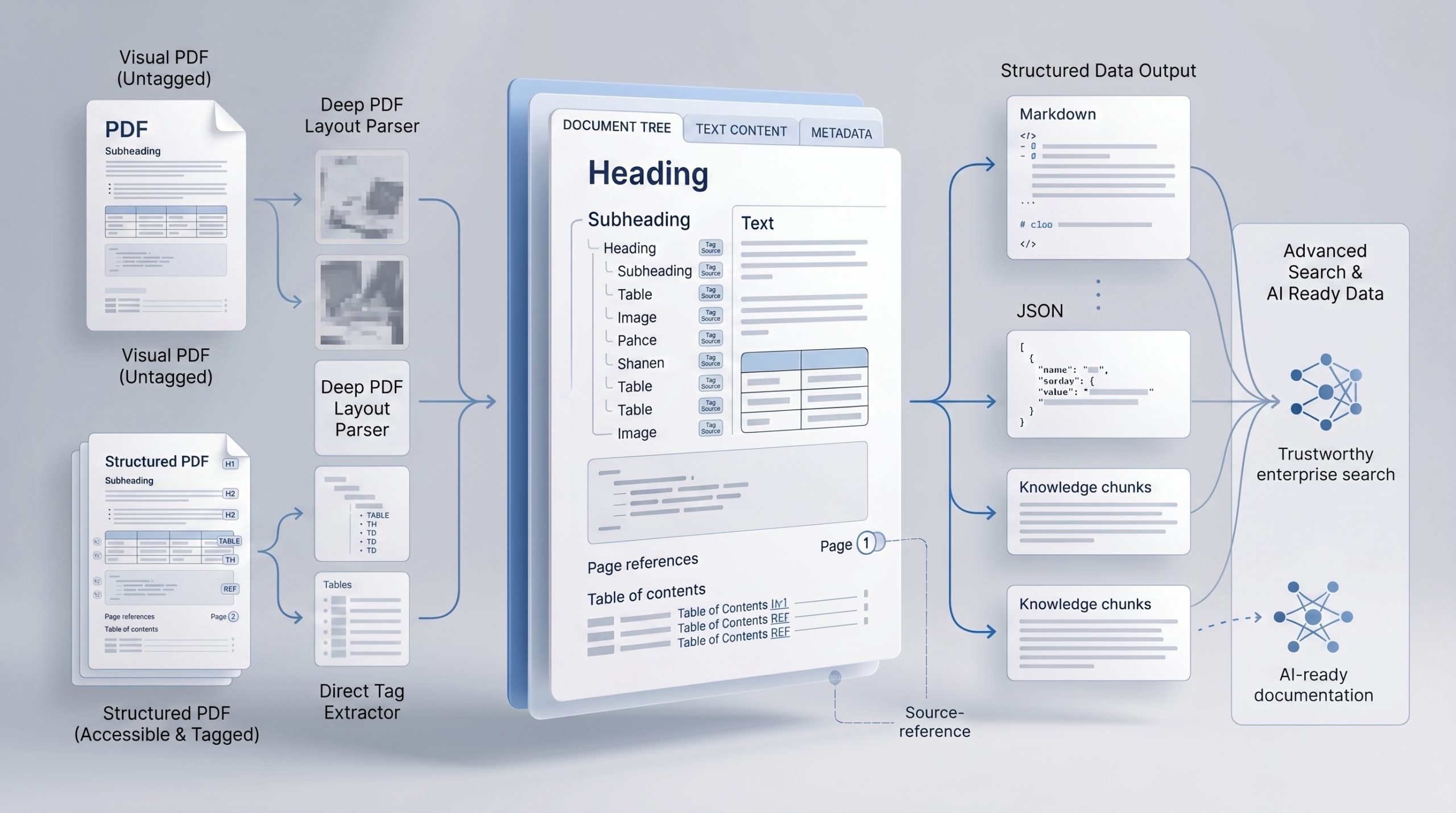
Ein PDF wirkt oft wie ein fertiges Dokument. Für Menschen stimmt das meistens. Für KI ist es komplizierter. Manche PDFs enthalten saubere Überschriften, Textfluss, Inhaltsverzeichnis und klar erkennbare Absätze. Andere PDFs sind eher gestaltete Seiten: Tabellen, Grafiken, Produktbilder, Diagramme, technische Zeichnungen, Fußnoten und Textblöcke, die nur im Layout zusammen Sinn ergeben. Wer solche Dokumente für KI, Suche oder einen Vector Store erfassen will, darf sie nicht alle gleich behandeln. Der richtige Weg hängt davon ab, ob das PDF vor allem Text enthält – oder ob seine Bedeutung aus der Seite als Ganzes entsteht.
Ein PDF ist kein Datenformat für Unternehmenswissen. Es ist ein Container. Entscheidend ist, ob darin strukturierter Text liegt oder eine gestaltete Grafik ist, die erst verstanden werden muss.
Warum diese Unterscheidung wichtig ist
Wenn ein Unternehmen Dokumentationen für KI nutzbar machen will, klingt der erste Schritt einfach: PDF einlesen, Text extrahieren, in den Vector Store schreiben.
Das funktioniert bei einfachen Dokumenten manchmal gut. Bei komplexen Dokumentationen funktioniert es oft schlecht.
Der Fehler liegt nicht im Ziel. Das Ziel ist richtig: Unternehmenswissen soll durchsuchbar, nutzbar und für KI verfügbar werden. Der Fehler liegt in der Annahme, dass jedes PDF auf dieselbe Art gelesen werden kann.
Ein sauberer Leitfaden aus Word ist etwas anderes als eine Herstellerdokumentation mit Maßzeichnungen. Ein Vertrag mit Fließtext ist etwas anderes als ein technisches Datenblatt. Eine Entwicklerdokumentation mit Codeblöcken ist etwas anderes als ein Produktkatalog mit Tabellen, Bildern und Variantenlogik.
Alle heißen PDF. Aber sie verhalten sich völlig unterschiedlich.
Strukturierte PDFs: Wenn Text wirklich Text ist
Es gibt PDFs, die aus gut strukturierten Quelldokumenten entstehen. Zum Beispiel aus Word, LaTeX, einem Redaktionssystem oder einer technischen Dokumentation mit klarer Kapitelstruktur.
Solche PDFs haben oft:
- Überschriften
- Absätze
- Listen
- Inhaltsverzeichnis
- Seitenzahlen
- Kapitelstruktur
- eingebetteten Text
- manchmal erkennbare Tabellen
Hier kann klassische Textextraktion sinnvoll sein. Der Text ist bereits vorhanden. Man muss ihn nicht zuerst als Bild betrachten, um ihn danach wieder als Text zu erkennen.
Bei solchen Dokumenten ist das Ziel nicht, alles neu zu interpretieren. Das Ziel ist, die vorhandene Struktur zu erhalten: Kapitel, Abschnitte, Überschriften, Listen, Codeblöcke und Quellenbezug.
Ein gutes Ergebnis sieht dann nicht wie ein großer Textblock aus, sondern wie sauberes Markdown oder JSON:
## 3.2 Benutzerrechte
Dieser Abschnitt beschreibt die Rollen im System.
- Administrator
- Projektmanager
- Standardbenutzer
Quelle: Dokumentation.pdf, Seite 14Das ist für KI gut nutzbar. Es ist lesbar, zitierbar und kann sinnvoll in Chunks aufgeteilt werden.
Visuelle PDFs: Wenn die Seite die Bedeutung trägt
Anders sieht es bei PDFs aus, deren Bedeutung stark vom Layout abhängt.
Das betrifft zum Beispiel:
- Herstellerdokumentationen
- Produktdatenblätter
- Katalogseiten
- technische Zeichnungen
- Montageanleitungen
- Diagramme
- Statistiken
- Screenshots
- Prozessgrafiken
- Tabellen mit Fußnoten
- Seiten mit mehreren Spalten
- Seiten mit Bild, Legende und Erklärung
Hier reicht reines Auslesen oft nicht aus. Es extrahiert Zeichen, aber nicht unbedingt Bedeutung.
Aus einer sauberen Produktseite wird dann ein Textbrei aus Werten, Begriffen und Fragmenten. Die KI findet später vielleicht „IP20“, „CRI“, „Lumen“ und „Montage“. Aber sie weiß nicht zuverlässig, welche Werte zusammengehören, welche Tabelle zu welcher Variante gehört und welche Fußnote nur für eine bestimmte Spalte gilt.
Für Unternehmenswissen ist das zu schwach.
Ein Mensch liest so eine Seite visuell. Er sieht Nähe, Struktur, Gruppen, Bildbezug und Hierarchie. Genau das muss bei der Erfassung berücksichtigt werden.
Warum einfaches PDF-to-Text oft scheitert
Viele einfache PDF-Pipelines behandeln Dokumente wie lineare Texte. Sie lesen Zeichen von Seite 1 bis Seite 200 aus und hoffen, dass daraus Wissen entsteht.
Bei komplexen PDFs passiert dann Folgendes:
Tabellen verlieren ihre Struktur. Spalten werden falsch zusammengesetzt. Bildunterschriften wandern an die falsche Stelle. Fußnoten stehen plötzlich mitten im Fließtext. Diagramme verschwinden ganz. Technische Zeichnungen werden ignoriert. Mehrspaltige Layouts werden in falscher Reihenfolge gelesen.
Das Ergebnis ist nicht leer. Das ist fast schlimmer.
Es enthält genug Text, um brauchbar auszusehen, aber zu wenig Struktur, um verlässlich zu sein.
Ein Vector Store mit solchem Material wirkt gefüllt. In Wirklichkeit speichert er viele Fragmente ohne sicheren Zusammenhang. Die KI antwortet dann nicht auf Basis von Wissen, sondern auf Basis schlecht zerlegter Dokumentreste.
Das ist ungefähr so, als würde man ein Ersatzteillager dadurch digitalisieren, dass man alle Teile in eine Kiste kippt und ein Foto davon macht.
Das Ziel ist nicht Textextraktion, sondern Wissensextraktion
Die entscheidende Frage lautet nicht: „Wie bekommen wir Text aus dem PDF?“
Die bessere Frage lautet: „Wie bekommen wir verlässliche Wissenselemente aus dem PDF?“
Ein Wissenselement kann ein Abschnitt sein. Oder eine Tabelle. Oder eine Bildbeschreibung. Oder ein Diagramm mit Erklärung. Oder ein Codebeispiel. Oder eine Warnung mit Bezug zu einem bestimmten Arbeitsschritt.
Für KI ist diese Struktur wichtiger als die reine Menge an Text.
Ein gutes Ziel-Format kann zum Beispiel so aussehen:
{
"document": "montageanleitung.pdf",
"page": 8,
"element_type": "table",
"title": "Empfohlene Abstände",
"content_markdown": "| Abstand | Anwendung | Hinweis |\n|---|---|---|\n| 50 cm | Wandmontage | Mindestwert |",
"source": "Seite 8, Tabelle unten"
}Das ist deutlich wertvoller als:
Empfohlene Abstände Abstand Anwendung Hinweis 50 cm Wandmontage MindestwertDer Unterschied ist nicht kosmetisch. Er entscheidet darüber, ob KI später belastbar arbeiten kann.
Der praktische Entscheidungsbaum
Vor dem Einlesen eines PDFs sollte man es grob klassifizieren.
Wenn das Dokument klar textbasiert ist, mit Überschriften, Kapiteln und sauberem Textfluss, dann ist klassische Extraktion oft ein guter Start. Danach muss der Inhalt bereinigt, strukturiert und in sinnvolle Abschnitte geteilt werden.
Wenn das Dokument stark visuell ist, sollte man vorsichtig sein. Dann ist es oft besser, Seiten als visuelle Einheiten zu behandeln. Die Seite wird gerendert, durch ein Vision-Modell analysiert und anschließend in strukturierte Elemente übertragen: Textblöcke, Tabellen, Diagramme, Bilder, Warnhinweise und Quellenbezug.
Bei gemischten Dokumenten braucht es beide Wege. Text dort, wo Text sauber vorliegt. Vision dort, wo Layout, Bild und Zusammenhang wichtig sind.
Der schlimmste Weg ist meist der bequemste: alles mit demselben Werkzeug einlesen und hoffen, dass der Vector Store es später schon richtet.
Der Vector Store richtet nichts. Er speichert nur, was man ihm gibt.
Kontext über Seitengrenzen hinweg
Ein weiteres Problem wird oft übersehen: Viele Dokumente erklären Inhalte über mehrere Seiten.
Eine Überschrift steht auf Seite 12, die Tabelle läuft auf Seite 13 weiter. Ein Codebeispiel beginnt unten auf einer Seite und endet oben auf der nächsten. Ein Diagramm wird erst im nächsten Absatz erklärt. Eine Produktvariante wird eingeführt, die Werte folgen später.
Deshalb reicht es bei komplexen PDFs oft nicht, nur eine einzelne Seite isoliert zu betrachten.
Ein praktischer Ansatz ist ein kleines Kontextfenster: vorherige Seite, aktuelle Seite, nächste Seite. Die aktuelle Seite wird extrahiert. Die Nachbarseiten liefern Orientierung. So bleiben laufende Tabellen, Codebeispiele, Erklärungen und Abschnittsbezüge besser erhalten.
Wichtig ist dabei eine saubere Trennung. Das Ergebnis muss klar markieren, was wirklich zur aktuellen Seite gehört und was nur als Kontext diente. Sonst wandert Inhalt versehentlich auf die falsche Seite.
Fazit
PDFs müssen vor der KI-Erfassung unterschieden werden.
Ein strukturiertes Text-PDF sollte anders behandelt werden als eine visuelle Herstellerdokumentation. Bei einfachen Dokumenten kann Textextraktion sinnvoll und effizient sein. Bei komplexen technischen PDFs ist sie oft zu schwach, weil sie Struktur und Bedeutung zerstört.
Das Ziel ist nicht, möglichst schnell Text aus PDFs zu holen. Das Ziel ist, verlässliche Wissenselemente zu erzeugen.
Für KI, Suche und Vector Stores zählt nicht, wie viel Text extrahiert wurde. Entscheidend ist, ob der Zusammenhang erhalten bleibt: Abschnitt, Tabelle, Bild, Diagramm, Fußnote, Quelle und Bedeutung.
Wer PDFs für KI nutzbar machen will, sollte deshalb mit einer einfachen Regel beginnen:
Erst Dokumenttyp verstehen. Dann Extraktionsweg wählen. Erst danach in den Vector Store.
Schreibe einen Kommentar